Git
- Difference between version and Version
- Remote repository VS local repository VS working copy
- Command line VS GUI tool
- Starting the project
- Using Git
- Conflicts
- Stashing
- Ignoring files
- Problems with EOLs
- What belongs into the repository?
- What does not belong to repository?
- Summary
Git is a popular Version Control System (VCS) used by many companies and individuals nowadays. But why use some VCS or what is it? I will try to answer these questions in this article.
You were probably overwhelmed by the amount of new information and approaches when you started to write your first programs. After a while, you were able to solve simple algorithmic tasks but the applications you made were more or less just Proofs of Concept (PoC) that some approach works. This course is focused on the making of a real-world usable application. Such thing is much bigger and complex than anything you created before. Yet, the project in this course is still a relatively small scale application.
Maybe you were happy that some functionality you just implemented works fine during the development of your project. Maybe you made some changes after, and something broke down terribly and working application became unusable. Maybe you thought: “What changes did I made during last hour? I need to go back and undo the modifications.”. Without ability to track changes in your sources you probably ended up with even messier code than before. Git gives you ability to store checkpoints of your code and possibility to revert to such checkpoint easily (and much more).
It is a good idea to store (previous) versions of your software somewhere. The simple way is to store archive files, snapshots of your current source code, somewhere on your drive. Better way is to use a system which can track changes (added and removed lines) in source code files and commit these changes as units of work into a repository. Git is such system. But there are other systems (SVN, Mercurial) and they work similarly.
Version control systems also allow branching of the code. It is useful for implementation of independent features. It means that from a certain point, you can have two (or more) alternative versions of your software. You can than choose to merge those branches into the main one or remove unused ones.
Another reason to use Git is that after some time, the size of projects you are going to work on will grow out of the scope of one person. The need to share changes in source code made by many programmers in parallel will make any other type of file exchange chaotic.
Advantage of using VCS:
- sharing your source code among computers which you use (you can work from home and from your workplace and you do not need to carry the files on a flash drive)
- sharing source code in team
- ability to branch source code and work on different features in parallel
- tracking history of changes
- tracking the author of those changes
- tracking the reason for such changes (when you have usable commit messages)
- ability to fire events when changes are committed into the repository
- your code is backed up on a remote computer
Disadvantages of using VCS:
- you have to follow some workflow guidelines
- you have to think about it and not forget to use it
Here is how Git GUI tool visualises changes in a source code:
This article is not a deep Git guide. It is just a overview of most basic Git commands and reasons to use Git. If you want to go deeper, read the Pro Git book.
Difference between version and Version
A Version is some planned release of your software: your team agreed to deliver 10 new features in 3 months and the Version will be 1.1.0. This is sometimes called a milestone. A version is just changed source code. You are creating new version of your code with each typed letter.
I deliberately used capital V to distinguish between two possible usages of word “version”, but this is not a rule. There are multiple ways how to assign version number for your software. You will probably not use version numbers for your project in this course.
Remote repository VS local repository VS working copy
A repository in Git is a graph of changes made to your source code. Each node in that graph represents a state of your source code files and each edge represent added or removed lines of code (the transition between those states).
You need a remote repository to share and backup your code. Your local repository has to be synchronised with remote repository to fetch changes made by others and to upload your changes. The working copy is the contents of your project folder. The easiest way to obtain a remote repository is to sign up for one of the freely available Git repository hosting:
Main remote repository is usually called origin. All programmers have their own local repositories which they have to synchronise with origin to download or upload changes.
You can use Git in local mode only – there would be no remote repository and no option to share code and no backup. But you will still be able to use branches and see history of changes.
Git repository hosting services are popular with Open Source software community. Those programmers share their code and ideas with the world on GitHub. You can download (clone) any repository and start exploring or contributing right now.
A branch is just a pointer to one of the graph’s nodes.
The state of the graph in your local repository does not have to be identical to state of the graph in remote repository or in repositories of other programmers. You can synchronise changes in given branch between repositories.
Command line VS GUI tool
Git is a command line tool – get used to it, many tools for programmers are only command line programs. You can download a GUI tool, but you should know what each command does before you can start using it. Graphical tool is priceless when you start working with branches.
Starting the project
There are two possible ways how to start using Git. One way is to begin a new project from scratch and start using Git once you decide that you need to. The other is to start contributing to an existing project with Git repository already available.
Initializing a repository in a folder and uploading it
Sometimes you just get and idea and start coding – although it is not the best approach, it happens. After a while, you see that the project is meaningful and you want to share the source code with others or you just want to have a private backup and history of changes. First, you have to setup a remote repository – this step is arbitrary for each repository hosting provider (you usually register and click “add repository” button). Then you have to initialise the local repository with these commands:
cd your/project/folder
git init
Do not forget to setup .gitignore file before adding files. Now you can use git add command to prepare files and
git commit command to create initial commit (read entire article first and than come back here to continue):
git add .
git commit -m "init"
Before pushing changes from your local to remote repository, you have to tell Git, where the remote repository is located. Most of Git hosting services have some kind of tutorial which will show customised commands:
git remote add origin git@bitbucket.org:your-login/name-of-repository.git
git push -u origin master
Origin is the name of main remote repository and master is the name of default main branch.
Cloning a repository
This is what we actually did in the second part of walkthrough when we downloaded
the project from Bitbucket to our local drive. All repository hosting services have some kind of “clone” button,
which shows URL of your repository or the whole git clone command.
cd your/project/folder
git clone <url> <target-path>
Target path can be . when you have already created an empty folder for your project.
SSH VS HTTPS
You can tell Git to communicate with remote repository using SSH protocol (you can upload your public key to repository
hosting to avoid typing login and password each time you want to communicate with remote) or you can use HTTPS protocol.
You can generate SSH key using system tools and store them in .ssh folder in your home directory (/home/login on
Linux or C:\Users\login on Windows).
Using Git
This is a quick list of most basic Git commands. Before you can start using Git, you should set up your name and email. All your commits will carry this information.
git config --global user.email "you@example.com"
git config --global user.name "Your Name"
Git obviously has to be installed first, you can download classic installer for Windows OS or use package manager on Linux.
Here is a link to Git cheatsheet. You can print it and look up Git commands when your memory fails you.
There is also a plenty of other “cheatsheets” online. Just type what you need plus “cheatsheet” keyword and select the one which fits your needs.
Basic workflow
When you work alone on a simple project, you will usually follow these steps:
git init
# OR
git clone <url> <target-path>
# synchronise your local repository with remote
git pull
# do your work here
git status
git add <path>
git commit -m "your message"
git push
# goto "gil pull", repeat forever
Yeah, just memorize these commands.
Status
This command will report changed files and files already staged (added) for commit.
git status
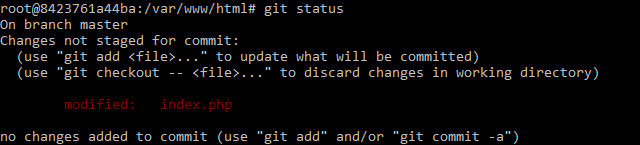
You can use git diff to actually see the changed lines.
Add
Prepare your changed files to be committed. You do not have to commit everything. Each commit should have single scope. That does not mean that each commit has to contain changes from just one file, but these changes should be related.
To add everything in current folder:
git add .
You can always revert added files using git reset <path>.
Commit
Actually storing changed files into the tree of changes. You have to specify a commit message. This creates a checkpoint in the history of your source code. Create small readable commits, all changes should be related and a suitable commit message should be supplied. If your company uses a ticketing system, include ID of issue.
git commit -m "some message"
Each commit has a unique hash. You can look up commits using that hash.
Remove last commit locally
Use git reset HEAD~ to remove commit and leave files in the current state. Use git reset --hard HEAD~ to
remove commit and revert files to previous state. To remove more commits use HEAD~<amout of commits to remove>,
e.g.: git reset HEAD~3.
Push
Synchronise your changes with remote repository (upload). It will fail when there are newer changes from another
programmer in the same branch. You have to download and integrate them first using git pull.
git push
Fetch and pull
Read documentation and documentation
The git pull command synchronises changes from remote repository (download). You should do this before you start
any work. There is a git fetch command which just peeks into the remote repository and tells you whether there
are any new commits.
git fetch
git pull
Branch and checkout
Read documentation and documentation
This is becoming interesting. You can find yourself in a situation when you have to make a decision between two possible implementations of a feature. Or you are not sure about how a feature would cooperate with rest of your project. You might want to branch your code and decide whether you want to incorporate changes later. Each branch has a name which you have to specify. Use meaningful names, you can use ID of feature request.
# create a branch
git branch feature
# switch branch
git checkout feature
You should use branches wisely to distinguish between finished and unfinished work. Branches are used by teams to avoid incorporating of unfinished work. You only merge a branch when somebody else approved it (tested and reviewed your code for given feature). There are multiple strategies of using branches and merging (and rebasing) but it is not in the scope of this article.
It is possible to switch between branches (using git checkout <branch-name> command), but you have to commit or stash
changes before doing so. This command effectively changes the contents of your project directory – working copy,
some files will change their contents or they may be removed at all, because different branch is in different state.
Do not worry, Git repository contains all committed work and when you switch back to previous branch, your files will
reappear again.
Merge
Once you decided that you need to incorporate changes made in a branch, you should merge it.
# switch to target branch
git checkout master
# merge changes
git merge feature
# delete merged branch
git branch -d feature
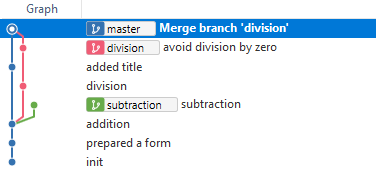
Conflicts
You will encounter conflicts in Git, you need to know how to resolve them. There is no way how to avoid this situation, there are only ways how to minimise their occurrence.
A conflict happens when two programmers made changes into same file on same lines. One of them (the quicker one) already committed and pushed his changes and the other one needs to solve the conflict. Git will report a conflict with a message and you are required to resolve the conflict before you can continue. A conflict can occur when work was done in same branch by two different people or when merging two branches into one.
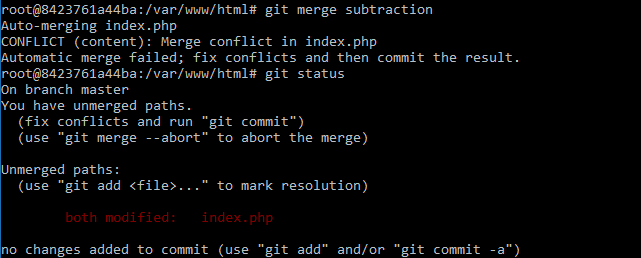
When this happens, use git status to see files with conflict. Use your editor to resolve conflict (make the code
runnable again) and than use git add <path> and git commit -m "resolve conflict message" to continue.
You can stop the merge by git merge --abort, this will revert both branches to previous state. Problematic
pieces of code are highlighted by Git like this in your files:
<<<<<<< HEAD
// code in current branch
=======
// code in merged-branch
>>>>>>> merged-branch
You can use different strategy to prevent conflicts, e.g.: you can agree to always use branches for all new features
implementations and dispatch git rebase command on each branch before merging the feature branch. That way the
programmer who wants to merge his changes into the codebase is responsible for solving the possible rebase conflict.
This is actually a good idea: share a branch with minimal amount of other programmers.
Stashing
You can stash changes without committing them. This is particularly useful when you have to implement hotfix on another branch and you are not yet ready to create a clean commit in your current branch.
# stash uncommited changes and reset files to last commit
git stash
# show stashed changes
git stash list
# apply changes from stash
git stash apply
Ignoring files
You should use .gitignore file to list unnecessary files (or folders). Changes in listed files (or folders) will
not be tracked by Git. You can have multiple ignore files in different folders of your project. Paths in .gitignore
are relative to that file.
Usual contents of .gitignore file for basic PHP project:
/vendor
/cache/*
/logs/*
/.env
*.log
Problems with EOLs
Git automatically converts end-of-line (EOL) characters in text files for current OS (Windows uses CR+LF but Unix based
systems use only LF). Sometimes you need to enforce Linux style end-of-lines (EOLs) – especially in bash scripts. You
can achieve this by creating .gitattributes file and setting something like this in it:
*.pl text eol=lf
*.sh text eol=lf
What belongs into the repository?
- a proper readme in markdown format (usually called
readme.md) - all source code files
- graphics used by your application (small images)
- some global config files (ideally customised for different environments)
composer.json(PHP),package.json(JS),Gemfile(Ruby),requirements.txt(Python) and similar files which are used to download required libraries for given programming language
What does not belong to repository?
- private config files (they would interfere with other programmers’ environment and they can contain secret passwords which is not responsible when you use public repository)
- large binary files (you can build your application from the sources)
- large data files (you can include small examples)
- log files
- your notes and test files
- shared libraries (you can download them using e.g. Composer on NPM)
- you never change files from libraries
Use .gitignore file to define ignored paths (see this section).
Summary
This article is a quick overview of basic Git commands and reasons to use VCS. You probably need to read a lot more about Git to be able to use it The Correct Way™. There are also GUI tools like SourceTree. You can list all available clients here.
Use Git, even for small projects, you will not learn how to use it properly without really working with it and solving different situations by yourself. It is hard sometimes and you will probably end up with messed repository many times. It will get better.
New Concepts and Terms
- Git
- Init
- Clone
- Add
- Commit
- Push
- Pull
- Branch
- Merge