Web
Before you can create a web application, it is quite important to understand what the web really is. Lets start at the very beginning.
Computer Networks
Computer networks (data networks) are systems for connecting computers together so that they communicate. Computer networks are one of the best standardized technologies used in IT. Computer networks are standardized on several levels. When you are working on a web application (and not on networking), you don’t need to get into too many details, so it suffices to distinguish between three levels:
- physical (OSI layer 1 and 2)
- logical (OSI layer 3 to 6)
- application layer (OSI layer 7)
Client-Server
When working with computer networks, you will often encounter the term client-server. A client-server is a relationship between two subjects. The server serves the client, i.e. it responds to requests sent by the client, tries to fulfill them and send back some response. Contrary to popular belief, a server is the passive subject and theoretically it should not do anything unless a client comes in with a request. The client is the active component and the one who gives orders to the server. The client sends a request to the server and receives a response from the server. The alternative to a client-server architecture is a Peer to Peer (P2P) architecture.
The client-server relation is not used only in the context of computer networks, it is used in many situations in IT. For example one may say that:
- A web browser is a client to a web server.
- A web browser is a client to the operating system.
- A computer user is a client to a web browser.
- A web server is client to a database server.
As you can see, a subject in the client-server relation does not have to be a computer. Nothing also prevents a server to someone to become a client to someone else. Therefore, when working with clients and servers in the context of networks, we talk about applications and roles, not about physical machines.
The following image shows how a random network looks on the application level view:
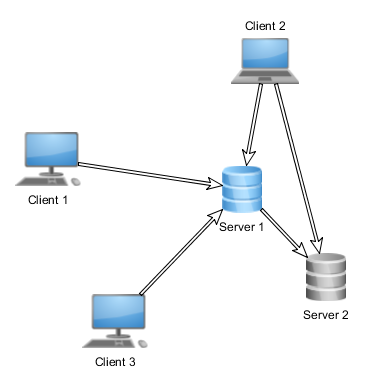
From the application point of view, you should interpret the above image as that:
- Client 3 is communicating with Server 1
- Client 2 is communicating with both Server 1 and Server 2
- Client 3 is not communicating with Server 2
The image tells you nothing about the physical network connections between the servers, actually it does not even tell you anything about the number of physical computers.
Physical level
Physical network level deals with connecting various devices (computers, phones, tablets, …) together. Each network device is connected through a network interface. For example if a computer can have both the ethernet cable connection and a WIFI wireless connection, it is connected through two network interfaces and – from the network point of view – acts as two unrelated network devices.
Logical level
Logical network level concentrates on organizing network devices into logical networks, addressing network devices and introduces basic communication protocols. Organizing devices into a logical network is crucial for maintainability, performance and security of the network. It also allows abstraction on top of the hardware arrangement. This means that you can establish a connection to your private/company/school network and act as if you were physically connected to that network, even if you are on the opposite side of the globe.
Application level
Application level focuses on providing some useful services to the network users. Application network level defines some protocols for those services and is open to new protocols for yet unknown services. Notice that on the logical level, there are also some network protocols defined, but those are primarily service protocols for running the network and data transfer protocols just for sending the data over.
Network protocol
Network protocol is (as any other protocol) a set of rules which are to be followed when communicating. Nothing prevents you from designing your own protocol, but it is a really good idea to start with the already existing ones. Network protocols are either text protocols (the communication is done through plain text content) or binary protocols.
By far the most common protocols are those from the TCP/IP protocol suite.
The Internet
An internet is a type of network which uses the TCP/IP protocol suite. The Internet is the largest (worldwide) of all internets. Because people have problems with using correct articles and capital letters, somebody invented the term intranet. Intranet is exactly the same as internet, only that it is definitely not the largest of them. An internet is a network which allows organizing computers into a hierarchical structure of sub-networks. This allows it to grow to a world-wide size, because having a single network with millions of computers is technically impossible. If you want an introduction to an internet structure, you can read How does the Internet work.
Standards of the Internet Network are published as RFC (Request for Comments). As the name suggests not all of RFCs are actually used as standards, but if you are unsure about something, do it as some RFC says. RFC standards are industrial standards – i.e. there is no law enforcing them, but every sane programmer follows them.
Internet protocols
The core protocol of an internet is IP (Internet Protocol). The Internet Protocol takes care of transmitting packets of data – i.e. delivering them from one network interface to another network interface. Other protocols are then built on top of the IP protocol. Apart from various service protocols for running the network, the important protocols are TCP (Transmission Control Protocol) and UDP (User Datagram Protocol).
TCP is a reliable protocol which means that it takes care of unreliability of the underlying network infrastructure and makes every effort to deliver the data without errors, including verification that they have been really delivered and not modified on the way.
UDP on the other hand is an unreliable protocol which means that it exposes all the unreliability of the network. The UDP protocol is used in cases where either the application takes care of the network unreliability by implementing its own mechanisms for verification. Or it is used in cases where such verification is not needed at all, in asynchronous communications (the sender does not wait for the response) or where speed is extremely important (real-time applications).
Internet Addressing
To transmit data between two network devices – a source host and a destination host, the protocol must be able to address the hosts. There are three basic types of network addresses:
- Physical Address (MAC address) – assigned by the manufacturer to the network interface card. A MAC address is reasonably unique worldwide and there should be low chance of encountering two network interfaces with the same MAC address. The MAC address is unusable in addressing at the application level (you would have to search the entire world to find the corresponding computer).
- Logical Address – usually an IP address – assigned by the network administrator (personally or through a DHCP server, or SLAAC). A logical address is usable for finding the right network, once there, it is translated to the physical address of the network interface for the actual data delivery.
- Name Address – assigned manually by the machine administrator, usable only for end-users. For communication it must always be translated to the logical address usually through a DNS server.
Note that while one logical address must correspond to one physical address (at a given time), the name address does not need to. A single computer with a single IP address may be assigned multiple domain names (e.g. www.example.com and example.com). Also a single domain name may be assigned multiple IP addresses – usually in case of load balancing and CDN.
Sockets
Once we know the logical network address, the IP protocol is able to figure out, where
the destination host lies physically and deliver data there. However, for two applications to communicate
this is still insufficient. Because multiple applications may be communicating on
a single device. To distinguish between all the communicating applications a socket is used.
A socket is a combination of address and port (delimited by a colon :). A network port is
simply a number between 1-65535 so an example socket can be 127.0.0.1:80.
There is one more twist to this. When a client wants to communicate with a server, the client initiates the connection. The server waits for the incoming connection on a particular network port (because there may be multiple servers running on a single computer) – it listens on a port. When the client initiates the connection, it must know on what port the server is listening. For that purpose a list of well-known ports which assigns port numbers to protocols is available. So for example, as long as the client is communicating with the HTTP protocol, it expects that the server will be listening on port 80. This way the request is delivered to the server. Then another problem arises – how to deliver the response. The server must know the address of the client for this purpose and it must also know the port of the application. Since there again may be multiple applications communicating with the server, the source port is chosen randomly from some range, the port is used only for the purpose of receiving the response, therefore it is ephemeral.
Network ports, network protocols and network services are all closely related together. A network service is an application offered in the (internet) network. It uses a communication protocol (a set of rules) and because of that it has a well-known port assigned to it. There is a number of services standardized in an internet network.
Internet Address Format
The addresses through many Internet services are encoded in URL format. The syntax of URL is:
protocol://user:password@address:port/path?query
The protocol part is a registered protocol name. user and password are optional credentials which are
not used so much anymore (because the password cannot be encrypted). address is either an IP address
or name address of the destination host. port is a socket port. path is a directory to the actual requested file.
query is name-value pairs optionally supplied to the requested file.
For example, when you enter ‘www.example.com’ in your web browser address field. The web browser
converts this to http://www.example.com because it knows it is a web browser and should communicate using
the HTTP protocol. Then the network layer converts this to http://www.example.com:80, because 80
is a well known port for the http protocol. Then this gets processed by the logical network layer and converted
to eg. http://10.20.30.40:80. Then the layer will send a request to this destination host and add
a source address with an ephemeral port – e.g. http://20.30.40.10:506070.
WWW service
WWW (World Wide Web) service or simply Web is one of the internet services. It is a system designed to provide linked text documents (web pages). The WWW Service uses the protocol HTTP (Hyper Text Transfer Protocol) for all communications. The HTTP protocol is one of the protocols in the TCP/IP protocol suite. The WWW service and the HTTP protocol are closely tied together, because HTTP describes the way in which a WWW client and server communicate. A WWW service client is an User Agent – commonly a Web Browser. The difference between a User Agent and a Web Browser is that a User Agent is more general. Other User Agents apart from Web Browsers are for example automated Web Robots or Screen Readers.
Web pages are created using the HTML language (Hyper-Text Markup Language). A hypertext is a text connected with other documents through links (see how it nicely fits together with the definition of WWW?). Web pages can be:
- static – The page content cannot be changed outside from the web server.
- dynamic – The page content is generated dynamically – usually from a database and responds to the end-user actions.
Web resource is anything which is provided by the WWW service. It can be a HTML page (only the HTML code),
images used in that page, downloadable content, etc. Each resource has
a MIME Type / Content Type. HTML pages have a MIME type text/html, PNG
images have the type image/png, etc. Modern web applications depend often on resources which
produce or consume data in JSON (application/json) or XML (application/xml) format, this is called an API,
but still is a web resource and communication is transported using the textual HTTP protocol.
Web application is a collection of (obviously) dynamic web pages, which together give the impression of a single coherent and compact application. Historically WWW service was never designed for this which yields to some technical drawbacks.
HTTP Protocol
An HTTP protocol splits communication into transactions. A HTTP Transaction consists of:
- establish connection (client)
- send request (client)
- send response (server)
- terminate connection (server)
HTTP is a text protocol. An HTTP request and response consist of headers and body. The headers contain metadata about the request and response (most importantly the Content type). A single HTTP transaction always contains a single WWW resource – e.g. a single HTML page, a single image, etc. Therefore many HTTP transactions are required to transfer an entire HTML page.
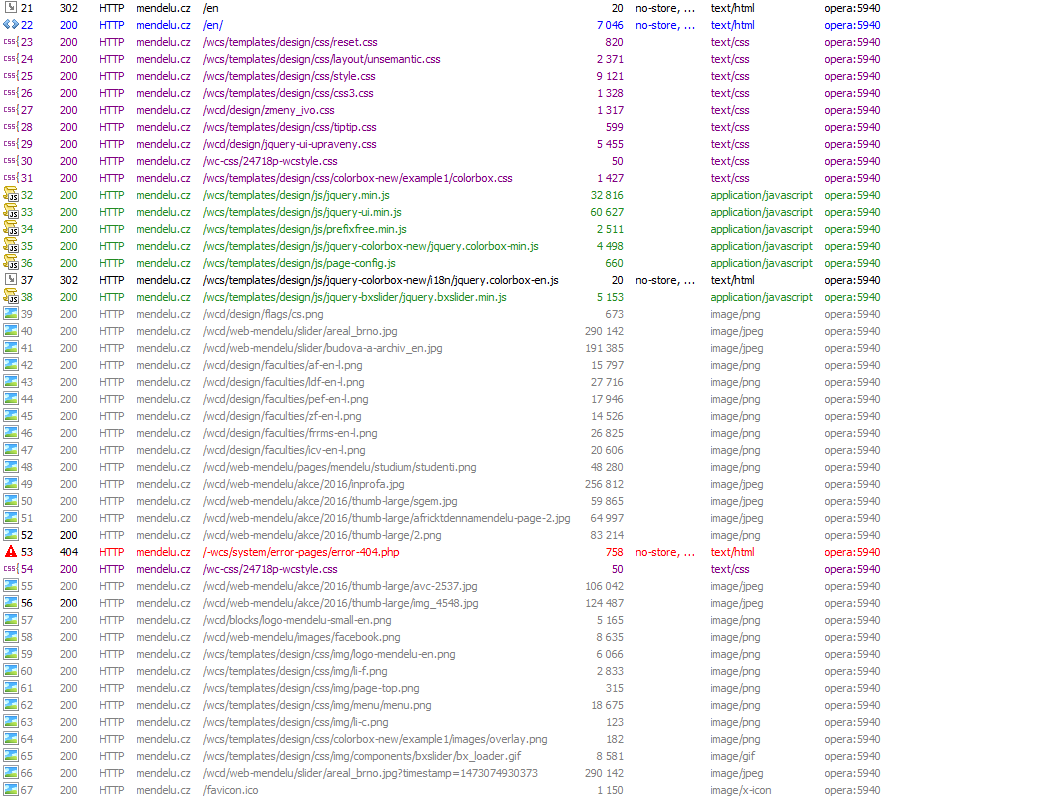
The image shows part of the HTTP requests list. The requests are sent when you visit the home page of http://mendelu.cz. Pink color shows the time of the DNS lookup, red color shows the time of connecting to the server, blue colour shows time during which the server is processing the request and generating the response, green colour shows the time required to transmit the response.
It is important to understand that what the end-user sees as a single coherent page are actually many HTTP requests which must be fulfilled individually. In case the web pages are dynamically generated by an application, the application will be started (and terminated) again for each request.
HTTP is a stateless protocol which means that transactions are isolated on the server. Each transaction creates a new HTTP connection. The server cannot reliably identify what requests come from a given client, this leads to the situation that no state retained between the transactions and all information about the web page state is lost.
This is something which was never a problem when there were only static pages - or simple dynamic pages. The statelessness of the HTTP protocol has far-reaching consequences. It has become a considerable problem for developing web applications which require some state. For example the application must ‘remember’ in its state which user is logged in. When a user enters credentials on the login page, the web application which processes the request is started, checks the credentials and responds with a successful login page. Then the user requests another page (e.g. list of her emails) and the application which processes the request is started again, unaware of what has happened before. To workaround the statelessness of the HTTP protocol, sessions and cookies must be used. Also, it makes all web statistics considerably skewed, because it is very hard to identify what a visit of a page is.
The above can be seen as a tradeoff for the effectiveness of the HTTP protocol and HTTP server – which is one the reasons why it has become so popular in the first place. The technology debt in this is being addressed by extensions to the HTTP protocol or new protocols (such as EventSource, WebSockets). These are already being used in practice, but it’s still a bit unclear what is the definitive winner technology.
Summary
The article describes what internet, web, HTTP, HTML are and what the relations between them are. These are technologies every IT person should be familiar with, but there is often a lot of confusion which I have tried to clear up here. Some very brief background to networking is also a necessary part of this.
New Concepts and Terms
- network layers
- network interface
- client-server
- addressing
- internet / intranet
- request / response
- network service
- network protocol
- reliable / unreliable protocol
- listening
- ephemeral port
- www service
- HTTP protocol
- static pages
- dynamic pages
- HTTP transaction
- stateless
- WWW resource