FAQ - Frequently asked questions
- Course and project related questions
- Can I have custom project assignment?
- Can I use different programming language?
- I am stuck with something, can I use help from a friend?
- I am stuck with something, can I use some piece of source code from a friend?
- Do I need to complete the course project before attending exam?
- How do I know that my project is OK?
- Lookup tables
- Questions (almost) impossible to answer
- General questions
- PHP questions
- Framework related questions (Slim)
- Templating engine questions
This place should navigate you quickly to important sections and tries to gather answers for questions of typical beginner.
Course and project related questions
Can I have custom project assignment?
It is possible to have a different assignment, but it has to be equally (or more) challenging as the default one. It has to use some database and it has to be implemented as a web application. Always consult alternative assignment with me.
Can I use different programming language?
Of course you can, but you have to write the project in a modern way. It means that you should use some framework, templating engine etc.
I am stuck with something, can I use help from a friend?
You are free to consult the project with anybody. Anyhow, the best bet is to ask me for help if you got really stuck. There is a chance that if you ask some of your more skilled friends who already solved the problem by “reinventing the wheel” that you will learn some bad habit. Some problems are very easy to solve but you have to be aware of certain methods – a good example is the problem of last insert ID value.
I am stuck with something, can I use some piece of source code from a friend?
Yes, but be careful. Your project will be considered as plagiarism if you copy more code than you wrote by yourself! Always remember to reference the original author!
//this code is from student XYZ (xyz@mendelu.cz)
function countRows(PDO $db, $table) {
$stmt = $db->query('SELECT COUNT(*) AS cnt FROM ' . $table);
return $stmt->fetch()['cnt'];
}
Do I need to complete the course project before attending exam?
It is recommended but you can present the project after your exam. Be aware that most of your classmates will have similar reasoning and they will postpone the presentation date as late as possible. It can happen, that few last days before the submission deadline will be crowded with project presentations and you will not manage to present your work in time.
How do I know that my project is OK?
First of all, try to use it. Every application has to be tested by a user (you or somebody else). Write down some scenarios (create a person with/without location, add multiple contacts to that person, move a person to another location, create a meeting and invite people, …) and try to perform them. You will see whether the app allows such actions to be executed and how smoothly they are carried out.
Keep in mind these key points when you design the application:
- somebody will use it from scratch (almost empty database).
- somebody will use it for two, three, four … or even more years.
- you want to install (sell) as many copies as possible to different users. They will have different requirement on contact/relation types.
Lookup tables
Those tables called contact_type and relation_type are lookup tables. They are there to customize the application
for different users (different instances of the same application). You should load records from them whenever you need
to specify contact or relation type in a form. Do not retype values from these tables into templates. If you do not
like that records in these tables are in English, change them to any other language in Adminer.
Wrong - this code does not reflect potential changes in lookup table:
<select name="idct">
<option value="1">Facebook</option>
<option value="2">Skype</option>
<option value="...">...</option>
</select>
Correct:
try {
$stmt = $this->db->query('SELECT * FROM contact_type ORDER BY name');
$tplVars['types'] = $stmt->fetchAll();
} catch (Exception $e) {
//log or show
}
<select name="idct">
{foreach $types as $t}
<option value="{$t['id_contact_type']}">{$t['name']}</option>
{/foreach}
</select>
Questions (almost) impossible to answer
How does it all work together? I have written (copied) all the code, it sort-of works, but I do not know why!
Well, working web application is a complicated thing. Do not trust anybody who tells you opposite. You have to know quite a lot of technologies (e.g. HTTP, HTML, CSS, PHP, SQL and a bit of JavaScript) to build one. The advantage of web technologies is that you only need a text-editor to code a HTML page or PHP script.
You have to study all building blocks separately and then connect all the ends together. Start with plain HTML, then try plain PHP, then generate some HTML code in PHP script. Important part are HTML forms and receiving values. Mix in some templating engine magic, add a framework and you are good to go. There is no simple answer for this, you have to study.
Should I use framework/library A instead of framework/library B, why you teach us Slim and Latte?
Well it depends… on lot of things (e.g. state and quality of documentation, state of development – is it still beta, size of developer community, how deeply is the technology rooted in community, is it new or old…). I tried to choose simple technologies which will give you a good start to learn more advanced ones later (especially frameworks).
Slim framework is simple and it suits very well for our task. For bigger application it would be better to use something
more sophisticated. Great advantage of Slim is that everything it does is traceable, there is very little magic –
e.g. database, logger and templating engine are defined in src/dependencies.php file. Request or Response objects
used as parameters of route handlers are well
documented and they are there to access input and
output of PHP script in object-oriented fashion. The middleware
mechanism is also very transparent.
Latte has very convenient syntax and good support in various editors (compare with syntax of Blade –
those @ macros look weird to me). Latte is also very secure and quite fast. Nevertheless the templating engines are
all alike.
My code is different than someone else’s, how is that possible?
There are multiple ways how to implement anything. It is OK to have your own way. Always try to read and understand code of other people, you can either enrich yourself with new knowledge or help somebody else. In the end, the user is most interested whether your application works or not.
General questions
How to start working on the project?
Simple answer is: have a plan! The more complicated answer follows. The walkthrough section covers only one module of the application – the person module (list, add, edit and delete actions). This module is obviously crucial but to fulfill the project assignment you have to do much more. A good idea is to write down all actions that you want to enable for users of your application before you start writing any code – a list or nested list is OK, UML Use-Case diagram is better. You can also identify user roles (like administrator, registered user or guest). Use-Case diagram includes user roles by its nature.
You can use dedicated software to draw UML diagrams. Try Visual Paradigm or Dia or just pencil and paper.
Here is an example of a Use-Case diagram made with PlantUML:
User in guest role can usually perform registration and login and optionally display public information.
Those Use-Cases are OK for high level understanding of the application scope, if you can’t see what particular bubble in that use case means, you can try Sequence diagrams. You should also specify initial conditions for each Use-Case - e.g. “user has to be logged in”, “there has to be record XY in the database” etc. There can also be alternative scenarios for each Use-Case - e.g. add a person with or without an address. Try also Activity diagram which is an extension of well-known flowchart diagram which is taught in basic programming courses.
Sometimes you can choose between more suitable UML diagrams, here is the same process (just the important part of it) modelled with Activity diagram:
Some UML diagrams are less intuitive than Use-Case, Activity or Sequence diagrams – they are focused on designing much more complicated systems than this application. Do not bother with Class or Object diagrams for now, you just need to be able to decompose the Use-Cases to individuals steps that can be rewritten as lines of your program.
Once you know what a user can do, you can start designing user interface for that actions. Take a pencil and a piece of paper and start drawing forms and layout of individual screens. You should create so called wireframe model for each screen of your application and you can append some notes to it. You should be able to identify required form fields from the supplied Entity-Relationship diagram. If you want to use software to draw wireframes, try Pencil project.
You may end up with something like this:
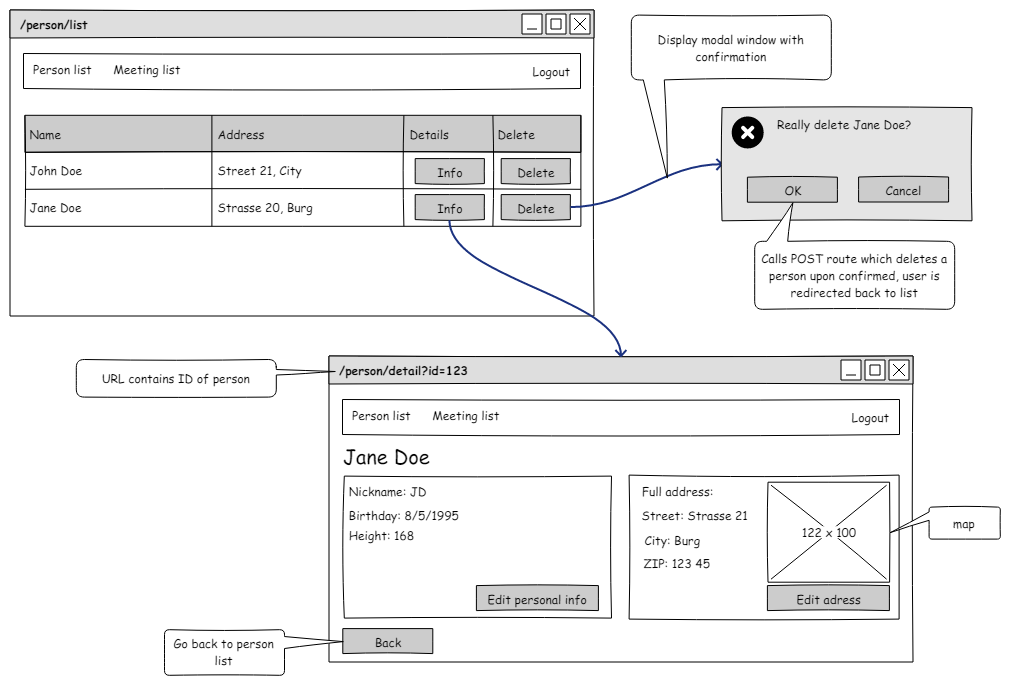
Some people start with wireframing first – it is up to you to decide whether you feel more confident drawing the user interface or thinking about all possible functions first.
After you have the wireframes with comments and list of actions, you can start coding: assign a route or filename to each action (depending on walkthrough version), prepare the template and display it – you can start with static templates. Afterwards start coding logic – retrieve data from database and display them (pass the data into template and show them to the visitor), prepare POST routes for data modifications when a page contains a form. Always think about what the user should see or where to redirect him after POST action.
I supplied the database structure for you so you do not have to bother designing it. In real world, you would have to analyse the assignment, find potential database entities and their attributes and create Entity-Relationship diagram by yourself. It is a good idea to crosscheck ERD with wireframe models of user interface to be sure that all forms and inputs are mapped to entities and attributes and vice-versa.
UML diagrams are nice, another, more important thing to know is the grasp of inner working of web applications, databases and related technologies – without this, you end up with Use-Case diagrams and superficial scenarios, sequence or activity diagrams and still no idea of how to start actually coding. To be able to write the code, you have to learn how to solve isolated problems and make a lot of prototypes. Read article about problem solving.
Why do we use some “framework”, how does it work?
Framework is a software which defines skeleton of your project and provides some basic means to write an application (e.g. logging and routing in Slim). Check out this walkthrough.
There are many frameworks for PHP, some of them provide more functionality and some of them less – Slim is a micro-framework and does not provide much functions, but it is very easy to use.
Framework is usually created by community of developers who share similar opinions about implementation of common functions. Each framework has documentation.
In reality, you always want to use some framework as you do not want to write your own solution for everything and you need to deliver results in reasonable time. Great advantage is that bugs in framework’s code are fixed by others (you just update to newer version). Once you learn to use one framework, you will find easier to learn and use another one – they all have similar core concepts.
Never write your own framework (unless you have 10+ years of experience and a team of developers and really lot of time).
When to use GET and when to use POST?
Generally, POST should be used to modify state (obviously to modify or remove record in database, less obviously for logout). Use GET whenever you want to let users revisit that same page in current state (e.g. save the link to favourites or share URL with others). You usually have one GET route and one POST route for forms – GET renders empty form and POST stores the values.
Take a look here.
PHP questions
My code is too long, how do I organise it?
Use include or require functions. Take a look here.
What is Composer and how do I install it?
Composer is a tool for downloading PHP libraries. You usually find a command in form
composer require someting on a web site of particular library which downloads the source code into /vendor folder.
The dependency is noted in composer.json file in the root of the project.
You can read more detailed description or try to use it.
Before you can use it on your computer, you have to install PHP as command line tool.
Framework related questions (Slim)
What is a route or routing?
Route is a combination of HTTP method (GET, POST or others) and a path, e.g. GET /persons or POST /new-person.
Routing is a mechanism which is implemented in a framework to map routes on actual code. You can use constructions
like $app->get('/some/route', function($request, $response, $args) { ... }) to match a route and a piece of code
which gets executed. If you are having difficulties to understand routing, think of a route as of IF statement:
$app->get('/some/route', function($request, $response, $args) {
//code
});
This code can be understood like the following one:
if($_SERVER['REQUEST_METHOD'] == 'GET' && $_SERVER['REQUEST_URI'] == '/some/route') {
//code
}
The variable $_SERVER is an actual thing which contains
some valuable information about the server where you execute PHP scripts and the request itself. Check out
phpinfo() function too.
Basic routing is explained in the walkthrough. Then check out this article and this walkthrough. Take a look at named routes too.
An important note is that routes are virtual, the paths in your address bar are not paths to actual files or folders. This magic is enabled by mod_rewrite plugin of Apache web server.
When to use getParsedBody() and when to use getQueryParam(...), what is the difference?
Both methods are used to get access to script inputs. Method getParsedBody() reads data from HTTP’s
body (hence the name of the method). The browser sends the information in the body when you use <form method="post">
(it packs the input names and values into a string and puts that string into the request payload – read that
HTTP article). Therefore this method is meaningful only in POST routes.
Method getQueryParam(...) fetches one parameter (given by its name) from the query. The query is part of the
URL and you can see it in the browser’s address bar. You can pass query parameters in links
(<a href="/route?param=value¶m2=value2">link</a>) and also in form’s action attribute. Therefore you can
use this method in either GET or POST routes.
Read more in walkthrough article about passing values.
There is also getQueryParams() function which returns all query parameters as associative array.
Templating engine questions
What is templating engine and why do we use it?
Templating engine is a library which takes as input HTML code with some macros in specific syntax and generates HTML code. We want to use it to divide PHP code and HTML code, because generating HTML in you PHP can look very ugly:
<?php
//connects a database
include('start.php');
echo '<!DOCTYPE html>';
echo '<html>';
echo '<head>';
echo '<meta charset="utf-8">';
echo '<title>Add a person</title>';
echo '</head>';
echo '<body>';
if(!empty($_POST['first_name']) && !empty($_POST['last_name']) && !empty($_POST['nickname'])) {
try {
$stmt = $db->prepare('INSERT INTO person
SET (first_name, last_name, nickname)
VALUES (:fn, :ln, :nn)');
$stmt->bindValue(':fn', $_POST['first_name']);
$stmt->bindValue(':fn', $_POST['last_name']);
$stmt->bindValue(':fn', $_POST['nickname']);
$stmt->execute();
echo '<span>Person created</span>';
} catch (Exception $e) {
echo '<span>Insertion of person failed.</span>';
}
} else if(!empty($_POST)) {
echo '<span>Set all required values.</span>';
}
?>
<form action="<?php echo $_SERVER['PHP_SELF']; ?>" method="post">
<label>First name</label>
<input type="text" name="first_name"
value="<?php echo !empty($_POST['first_name']) ? $_POST['first_name'] : ''; ?>">
<br>
<label>Last name</label>
<input type="text" name="last_name"
value="<?php echo !empty($_POST['last_name']) ? $_POST['last_name'] : ''; ?>">
<br>
<label>Nickname</label>
<input type="text" name="nickname"
value="<?php echo !empty($_POST['nickname']) ? $_POST['nickname'] : ''; ?>">
<br>
<input type="submit" value="Save">
</form>
<?php
echo '</body>';
echo '</html>';In the example above, note that HTML in echo is just a string, therefore it is tedious and error prone to write code
this way.
It has many benefits:
- separation of concerns – PHP and HTML in separate files, different people with different specialisation can work independently, there is an interface between template and PHP code (names of variables)
- security (no XSS)
- real approach – templating is common approach to generate HTML code
How does template engine work
It transforms HTML code with macros to executable PHP code. The actual code that get executed is the PHP file generated by this transformation.
Here is a quick example of templating engine input and possible output:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>{$title|capitalize}</title>
</head>
<body>
{if $something}
<p>
{$somethingElese}
</p>
{/if}
</body>
</html>
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title><?php htmlspecialchars(strtoupper($title)); ?></title>
</head>
<body>
<?php if($something) { ?>
<p>
<?php echo htmlspecialchars($somethingElese); ?>
</p>
<?php } ?>
</body>
</html>
That thing behind | is a filter – it is a convenient way to transform
values in template.
How do the variables come into the template?
There is an interface between a PHP code and a template. PHP simply pushes variables into template and template tells, what variable it needs to work (if it is documented). Templating engine usually receives an associative array. The keys in that array are extracted and become variables in context of transformed template (actual PHP code – see previous question).
The tricky part is, when you need to pass an array into the template (i.e. a result of database query). Arrays in PHP can be multi-dimensional, and you can combine associative and ordinal arrays together. See following example.
PHP code:
$app->get(function($request, $response, $args) {
$tplVars = []; //an empty array
$tplVars['title'] = 'Title of a page'; //a key title with a scalar value
$tplVars['data'] = [ //a key data which contains another ordinal array (no keys given)
[ //but this array contains yet another associative arrays!
'first_name' => 'John',
'last_name' => 'Test'
],
[
'first_name' => 'Jane',
'last_name' => 'Example'
]
];
//$tplVars['data'][0]['first_name'] contains 'John'
//$tplVars['data'][1]['last_name'] contains 'Example'
return $this->view->render($response, 'template.latte', $tplVars);
});
Template will have access to scalar variable $title and array $data:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>{$title}</title>
</head>
<body>
{foreach $data as $v}
<p>
{$v['first_name']} {$v['last_name']}
</p>
{/foreach}
</body>
</html>
Result that is received by the browser:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Title of a page</title>
</head>
<body>
<p>
John Test
</p>
<p>
Jane Example
</p>
</body>
</html>
Templating engine errors are difficult to read and point to strange places.
This is unfortunately true. The source of this problem comes from the general idea of templating engine itself – it transforms HTML code with macros to executable PHP code. The actual code that get executed is the PHP file somewhere in cache and therefore the errors are so difficult to read.
You can open the compiled template in cache and look for the line with error. You should be able to identify problem source by the surrounding HTML code. Read more in debugging article.